
Veritas cluster Interview Questions
Veritas
cluster interview questions & answers part -2 will help you to
overcome from L3 level VCS interview which will be asked frequently for
SME position across many organizations.
Here
is the Top:30 VCS interview questions for you.
Please go through questions and answers. Let me know if you have any doubt by leaving comment.
Adding and removing cluster node
Q-1 How to add a node in an existing cluster?
Ans: Adding a node into an existing cluster is a multi steps process.
1: Set up the hardware
Before adding a node to an existing cluster, node must be physically connected with the cluster.
1: Connect the VCS private Ethernet controllers
2: Connect the node to the shared storage
2: Install the VCS software in the node
Install the VCS software and install the license.
3: Configure LLT and GAB
Create the LLT & GAB configuration files (/etc/llthosts, /etc/llttab and /etc/gabtab) in the new node and update the files on the existing node.
4: Add the node to an existing cluster
We have to perform below given tasks in any of the existing node of a cluster
1:Make to cluster configuration R/W
# haconf –makerw
2:Add the new node to the cluster
# hasys –add
3:Copy main.cf file from an existing node to new node
# scp /etc/VRTSvcs/conf/config/main.cf new_node:/
/etc/VRTSvcs/conf/config/main.cf
4:Start vcs on the new node
# hastart
5:Now make the configuration again read only.
# haconf –dump –makero
5: Start VCS and verify the cluster
1:Start VCS on the new node
# hastart
6: Run the GAB configuration command on each node to verify that port a and port h include the new node in the membership.
# /sbin/gabconfig -a
Q-2 How to remove a node from an existing cluster?
Ans: Removing a node from a cluster includes many steps, which are given below:
1: Backup the configuration file
# cp /etc/VRTSvcs/conf/config/main.cf /etc/VRTSvcs/conf/config/main.cf.orig
2: Check the status of the nodes and the service groups
# hastatus –summary
3: Switch service group which is online on the node leaving the cluster
# hagrp –switch to
4: Delete the node from the VCS configuration
1: Make the cluster configuration R/W
# haconf –makerw
2: Stop the cluster on leaving node
# hastop –sys
3: Delete the leaving node from the service group’s SystemList attribute.
# hagrp –modify SystemList –delete
4: Delete the node from the cluster
# hasys –delete
5: Now again make the cluster configuration Read Only.
# haconf –dump –makero
5: Modify the LLT and GAB configuration files to reflect changes
Modify /etc/llthosts, /etc/llttab and /etc/gabtab files on the remining node on the cluster.
6: Remove VCS configuration on the node leaving the cluster
1: Unconfigure and unload LLT and GAB
# /sbin/gabconfig –U
# /sbin/lltconfig –U
2: Unload the LLT and GAB modules
# modunload –i
# modunload –I
3: Rename the startup files to prevent LLT, GAB and VCS from
starting up in future.
# mv /etc/rc2.d/S70llt /etc/rc2.d/s70llt
# mv /etc/rc2.d/S92gab /etc/rc2.d/s92gab
# mv /etc/rc3.d/S99vcs /etc/rc3.d/s99vcs
4: Remove VCS package from the node
Some General Questions:
Q-1 How to shutdown a node in VCS cluster?
Ans: Shutting down a VCS node is multi step process.
1) Make the cluster configuration Read/Write
# haconf –makerw
2) Either Switchover or failover all the service group which are online on shutting down node to remaining node
# hagrp –switch -to
3) Freeze all the service group which are online in the cluster.
# hagrp –freeze -persistent
4) Stop the cluster on the node that is going to be down.
# hastop –local –force
5) Rename the VCS startup script
# cd /etc/rc3.d
# mv S99vcs s99vcs
6) Now reboot the box.
Once the system will come up after reboot, Follow the below given instructions.
1) Start the VCS on this node
# hastart –force
2) Make the service group online if they were made offline before the system down.
# hagrp –online -sys
3) Unfreeze all the service groups which are frozen.
# hagrp -unfreeze -persistent
4) Now make the cluster configuration Read-Only
# haconf -dump –makero
5) Now again move back the VCS startup script
# cd /etc/rc3.d
# mv s99vcs S99vcs
Q-2 How do check the status of VERITAS Cluster Server?
Ans: hastatus –sum
Q-3 Which is the main config file for VCS and where it is located?
Ans: main.cf is the main configuration file for VCS and it is located in /etc/VRTSvcs/conf/config.
Q-4 Which command you will use to check the syntax of the main.cf?
Ans: hacf -verify /etc/VRTSvcs/conf/config
Q-5 How will you check the status of individual resource of VCS cluster?
Ans: hares –state
Q-6 What is the service group in VCS?
Ans: Service group is made up of resources and their links which you normally requires to maintain the HA of application.
Q-7 What is the use of halink command?
Ans: halink is used to link the dependencies of the resources
Q-8 What is the difference between switchover and failover?
Ans: Switchover is an manual task where as failover is automatic. You can switchover service group from online cluster node to offline cluster node in case of power outage, hardware failure, schedule shutdown and reboot. But the failover will failover the service group to the other node when VCS heartbeat link down, damaged, broken because of some disaster or system hung.
Q-9 What is the use of hagrp command?
Ans: hagrp is used for doing administrative actions on service groups like online, offline, switch etc.
Q-10 How to switchover the service group in VCS?
Ans: hagrp –switch to
Q-11 How to online the service groups in VCS?
Ans: hagrp –online -sys
Q-12 How to access the VCS cluster management console?
Ans: VCS cluster management console can be accessed by the below given URLs:
http://Servername:8181/cmc/
or
https://Servername:8443/cmc
Q-13 How to access the Cluster Manager Java Console?
Ans: #/opt/VRTSvcs/bin/hagui
Q-14 What is Jeopardy?
Ans: When a node in the cluster is having only one interconnected link remaining, then it’s very difficult for GAB to discriminate between system or network failure. A special membership category takes effect in this situation, called jeopardy membership. This memebship prevent cluster from split brain condition. When a system is placed in jeopardy membership, two actions occur:
1: Service groups running on this node placed in auto disabled state. A service group in auto disabled state may failover on a resource or group fault but can’t failover on system fault.
2: VCS operates the cluster as a single node cluster. Other systems in the clusters are partitioned off in a separate cluster membership.
Q-15 What is the main daemon of VCS?
Ans: had (high availability daemon) which is started by hashadow daemon.
Q-16 What is GAB?
Ans: Group Membership Services/Atomic Broadcast (GAB) is responsible for cluster membership and reliable cluster communication. GAB has two major functions:
1: Cluster membership
GAB maintains cluster membership by receiving heartbeat from LLT. When a system no longer receives heartbeats from a cluster peer, GAB marks the node as down.
2: Cluster communication
GAB provides the guranteed delivery of messages to all the systems. The atomic broadcast functionality is used by HAD to ensure that all systems within the cluster receive configuration change messages.
Q-17 What is LLT?
Ans: Low Latency Transport (LLT) is used for all cluster communication. LLT has 2 major functions:
1: Traffic Distribution
LLT works as a backbone for GAB. LLT distributes all inter communication across all configured network links. If a link is failes, traffic is directed to the remaining link.
2: Heartbeat
LLT is responsible for sending and receiving heartbeat signals.
Q-18 How many network links are supported in LLT?
Ans: 8 links are supported.
Q-19 How many nodes can join a Cluster?
Ans: Maximum of 32 nodes is supported in VCS.
Q-20 What is heartbeat?
Ans: Heartbeat is an Ethernet broadcast packet. This packet notifies all othe nodes that sender is functional. This is the only broadcast traffic generated by VCS. Each node sends 2 hearbeat packets per second per interface. Heartbeat is used by GAB to determine cluster membership.
Q-21 What is split brain condition?
Ans: When all the cluster interconnected links fail, it is possible for one cluster to separate into 2 subclusters, each of which doesn’t know about the other subcluster. The two subclusters could each carry out recovery actions for the departed system. For example two systems could try to import the same storage and cause data corruption.
Q-22 How do you shutdown a Veritas Cluster Server, leaving the applications running from the command line?
Ans: # hastop -all -forceQ-23 What is coordinator disk?
Ans: Coordinator disks are three standard disks or LUNs set aside for I/O fencing during cluster reconfiguration. Coordinator disks do not serve any other storage purpose in the VCS configuration. These disks provide a lock mechanism to determine which nodes get to fence off data drives from other nodes. A node must eject a peer from the coordinator disks before it can fence the peer from the data drives. This concept of racing for control of the coordinator disks to gain the ability to fence data disks is key to understanding prevention of split brain through fencing.
Please go through questions and answers. Let me know if you have any doubt by leaving comment.
Adding and removing cluster node
Q-1 How to add a node in an existing cluster?
Ans: Adding a node into an existing cluster is a multi steps process.
1: Set up the hardware
Before adding a node to an existing cluster, node must be physically connected with the cluster.
1: Connect the VCS private Ethernet controllers
2: Connect the node to the shared storage
2: Install the VCS software in the node
Install the VCS software and install the license.
3: Configure LLT and GAB
Create the LLT & GAB configuration files (/etc/llthosts, /etc/llttab and /etc/gabtab) in the new node and update the files on the existing node.
4: Add the node to an existing cluster
We have to perform below given tasks in any of the existing node of a cluster
1:Make to cluster configuration R/W
# haconf –makerw
2:Add the new node to the cluster
# hasys –add
3:Copy main.cf file from an existing node to new node
# scp /etc/VRTSvcs/conf/config/main.cf new_node:/
/etc/VRTSvcs/conf/config/main.cf
4:Start vcs on the new node
# hastart
5:Now make the configuration again read only.
# haconf –dump –makero
5: Start VCS and verify the cluster
1:Start VCS on the new node
# hastart
6: Run the GAB configuration command on each node to verify that port a and port h include the new node in the membership.
# /sbin/gabconfig -a
Q-2 How to remove a node from an existing cluster?
Ans: Removing a node from a cluster includes many steps, which are given below:
1: Backup the configuration file
# cp /etc/VRTSvcs/conf/config/main.cf /etc/VRTSvcs/conf/config/main.cf.orig
2: Check the status of the nodes and the service groups
# hastatus –summary
3: Switch service group which is online on the node leaving the cluster
# hagrp –switch
4: Delete the node from the VCS configuration
1: Make the cluster configuration R/W
# haconf –makerw
2: Stop the cluster on leaving node
# hastop –sys
3: Delete the leaving node from the service group’s SystemList attribute.
# hagrp –modify
4: Delete the node from the cluster
# hasys –delete
5: Now again make the cluster configuration Read Only.
# haconf –dump –makero
5: Modify the LLT and GAB configuration files to reflect changes
Modify /etc/llthosts, /etc/llttab and /etc/gabtab files on the remining node on the cluster.
6: Remove VCS configuration on the node leaving the cluster
1: Unconfigure and unload LLT and GAB
# /sbin/gabconfig –U
# /sbin/lltconfig –U
2: Unload the LLT and GAB modules
# modunload –i
# modunload –I
3: Rename the startup files to prevent LLT, GAB and VCS from
starting up in future.
# mv /etc/rc2.d/S70llt /etc/rc2.d/s70llt
# mv /etc/rc2.d/S92gab /etc/rc2.d/s92gab
# mv /etc/rc3.d/S99vcs /etc/rc3.d/s99vcs
4: Remove VCS package from the node
Some General Questions:
Q-1 How to shutdown a node in VCS cluster?
Ans: Shutting down a VCS node is multi step process.
1) Make the cluster configuration Read/Write
# haconf –makerw
2) Either Switchover or failover all the service group which are online on shutting down node to remaining node
# hagrp –switch
3) Freeze all the service group which are online in the cluster.
# hagrp –freeze
4) Stop the cluster on the node that is going to be down.
# hastop –local –force
5) Rename the VCS startup script
# cd /etc/rc3.d
# mv S99vcs s99vcs
6) Now reboot the box.
Once the system will come up after reboot, Follow the below given instructions.
1) Start the VCS on this node
# hastart –force
2) Make the service group online if they were made offline before the system down.
# hagrp –online
3) Unfreeze all the service groups which are frozen.
# hagrp -unfreeze
4) Now make the cluster configuration Read-Only
# haconf -dump –makero
5) Now again move back the VCS startup script
# cd /etc/rc3.d
# mv s99vcs S99vcs
Q-2 How do check the status of VERITAS Cluster Server?
Ans: hastatus –sum
Q-3 Which is the main config file for VCS and where it is located?
Ans: main.cf is the main configuration file for VCS and it is located in /etc/VRTSvcs/conf/config.
Q-4 Which command you will use to check the syntax of the main.cf?
Ans: hacf -verify /etc/VRTSvcs/conf/config
Q-5 How will you check the status of individual resource of VCS cluster?
Ans: hares –state
Q-6 What is the service group in VCS?
Ans: Service group is made up of resources and their links which you normally requires to maintain the HA of application.
Q-7 What is the use of halink command?
Ans: halink is used to link the dependencies of the resources
Q-8 What is the difference between switchover and failover?
Ans: Switchover is an manual task where as failover is automatic. You can switchover service group from online cluster node to offline cluster node in case of power outage, hardware failure, schedule shutdown and reboot. But the failover will failover the service group to the other node when VCS heartbeat link down, damaged, broken because of some disaster or system hung.
Q-9 What is the use of hagrp command?
Ans: hagrp is used for doing administrative actions on service groups like online, offline, switch etc.
Q-10 How to switchover the service group in VCS?
Ans: hagrp –switch
Q-11 How to online the service groups in VCS?
Ans: hagrp –online
Q-12 How to access the VCS cluster management console?
Ans: VCS cluster management console can be accessed by the below given URLs:
http://Servername:8181/cmc/
or
https://Servername:8443/cmc
Q-13 How to access the Cluster Manager Java Console?
Ans: #/opt/VRTSvcs/bin/hagui
Q-14 What is Jeopardy?
Ans: When a node in the cluster is having only one interconnected link remaining, then it’s very difficult for GAB to discriminate between system or network failure. A special membership category takes effect in this situation, called jeopardy membership. This memebship prevent cluster from split brain condition. When a system is placed in jeopardy membership, two actions occur:
1: Service groups running on this node placed in auto disabled state. A service group in auto disabled state may failover on a resource or group fault but can’t failover on system fault.
2: VCS operates the cluster as a single node cluster. Other systems in the clusters are partitioned off in a separate cluster membership.
Q-15 What is the main daemon of VCS?
Ans: had (high availability daemon) which is started by hashadow daemon.
Q-16 What is GAB?
Ans: Group Membership Services/Atomic Broadcast (GAB) is responsible for cluster membership and reliable cluster communication. GAB has two major functions:
1: Cluster membership
GAB maintains cluster membership by receiving heartbeat from LLT. When a system no longer receives heartbeats from a cluster peer, GAB marks the node as down.
2: Cluster communication
GAB provides the guranteed delivery of messages to all the systems. The atomic broadcast functionality is used by HAD to ensure that all systems within the cluster receive configuration change messages.
Q-17 What is LLT?
Ans: Low Latency Transport (LLT) is used for all cluster communication. LLT has 2 major functions:
1: Traffic Distribution
LLT works as a backbone for GAB. LLT distributes all inter communication across all configured network links. If a link is failes, traffic is directed to the remaining link.
2: Heartbeat
LLT is responsible for sending and receiving heartbeat signals.
Q-18 How many network links are supported in LLT?
Ans: 8 links are supported.
Q-19 How many nodes can join a Cluster?
Ans: Maximum of 32 nodes is supported in VCS.
Q-20 What is heartbeat?
Ans: Heartbeat is an Ethernet broadcast packet. This packet notifies all othe nodes that sender is functional. This is the only broadcast traffic generated by VCS. Each node sends 2 hearbeat packets per second per interface. Heartbeat is used by GAB to determine cluster membership.
Q-21 What is split brain condition?
Ans: When all the cluster interconnected links fail, it is possible for one cluster to separate into 2 subclusters, each of which doesn’t know about the other subcluster. The two subclusters could each carry out recovery actions for the departed system. For example two systems could try to import the same storage and cause data corruption.
Q-22 How do you shutdown a Veritas Cluster Server, leaving the applications running from the command line?
Ans: # hastop -all -forceQ-23 What is coordinator disk?
Ans: Coordinator disks are three standard disks or LUNs set aside for I/O fencing during cluster reconfiguration. Coordinator disks do not serve any other storage purpose in the VCS configuration. These disks provide a lock mechanism to determine which nodes get to fence off data drives from other nodes. A node must eject a peer from the coordinator disks before it can fence the peer from the data drives. This concept of racing for control of the coordinator disks to gain the ability to fence data disks is key to understanding prevention of split brain through fencing.
Q-24
What is IO fencing and how to configure IO fencing?
Ans: IO fencing is a feature that prevents data corruption in the event of a communication breakdown in a cluster. IO fencing is used to remove the risk associated with split brain condition. I/O fencing allows write access for members of the active cluster and blocks access to storage from non-members; even a node that is alive is unable to cause damage.
Q-25 How to upgrade VCS?
Ans:
1) Removing the deprecated resource type
2) Start the installvcs program which is under the directory cluster_server
Q-26 How to perform minimal downtime up-gradation in VCS?
Q-27 How to upgrade Solaris OS in which VCS is running?
Ans: To upgrade a Solaris OS in which VCS is running, Follow the below instruction:
1) Stop VCS on this node
Make the VCS configuration R/W
# haconf –makerw
Move all service groups from this node to another node and freeze this node:
# hasys –freeze –persistent –evacuate
# Make the cluster configuration Read/Only?
# haconf –dump –makero
# Stop the cluster on this node
# hastop –force –local
2) Stop, unconfigure and unsinstall LLT and GAB on this node
Unconfigure GAB
# gabconfig –U
Unconfigure LLT
# lltconfig –U
Now remove GAB and LLT packages
# pkgrm VRTSgab VRTSllt
3) Now upgrade Solaris and switch to single user mode
4) Now Install and configure LLT and GAB
# pkgadd –d . VRTSgab VRTSllt
5) Now switch to multi user mode and start VCS
# init 3
# hastart
6) Now unfreeze this node
# hasys –unfreeze –persistent
# haconf –dump –makero
Ans: IO fencing is a feature that prevents data corruption in the event of a communication breakdown in a cluster. IO fencing is used to remove the risk associated with split brain condition. I/O fencing allows write access for members of the active cluster and blocks access to storage from non-members; even a node that is alive is unable to cause damage.
Q-25 How to upgrade VCS?
Ans:
1) Removing the deprecated resource type
2) Start the installvcs program which is under the directory cluster_server
Q-26 How to perform minimal downtime up-gradation in VCS?
Q-27 How to upgrade Solaris OS in which VCS is running?
Ans: To upgrade a Solaris OS in which VCS is running, Follow the below instruction:
1) Stop VCS on this node
Make the VCS configuration R/W
# haconf –makerw
Move all service groups from this node to another node and freeze this node:
# hasys –freeze –persistent –evacuate
# Make the cluster configuration Read/Only?
# haconf –dump –makero
# Stop the cluster on this node
# hastop –force –local
2) Stop, unconfigure and unsinstall LLT and GAB on this node
Unconfigure GAB
# gabconfig –U
Unconfigure LLT
# lltconfig –U
Now remove GAB and LLT packages
# pkgrm VRTSgab VRTSllt
3) Now upgrade Solaris and switch to single user mode
4) Now Install and configure LLT and GAB
# pkgadd –d . VRTSgab VRTSllt
5) Now switch to multi user mode and start VCS
# init 3
# hastart
6) Now unfreeze this node
# hasys –unfreeze –persistent
# haconf –dump –makero
Veritas Cluster (VCS) Questions
1.How do check the status of VERITAS Cluster Server ?
Ans: hastatus –sum
2. Which is the main config file for VCS and where it is located?
Ans: main.cf is the main configuration file for VCS and it is located in /etc/VRTSvcs/conf/config.
3. Which command you will use to check the syntax of the main.cf ?
Ans: hacf -verify /etc/VRTSvcs/conf/config
4. How will you check the status of individual resources of VCS cluster?
Ans: hares –state
5. What is the service group in VCS ?
Ans: Service group is made up of resources and their links which you normally requires to maintain the HA of application.
6. What is the use of halink command ?
Ans: halink is used to link the dependencies of the resources
7. What is the difference between switchover and failover ?
Ans: Switchover is an manual task where as failover is automatic. You can switchover service group from online cluster node to offline cluster node in case of power outage, hardware failure, schedule shutdown and reboot. But the failover will failover the service group to the other node when VCS heartbeat link down, damaged, broken because of some disaster or system hung.
8. What is the use of hagrp command ?
Ans: hagrp is used for doing administrative actions on service groups like online, offline, switch etc.
9. How to switchover the service group in VCS ?
Ans: hagrp -switch (service_group) -to (system_name)
10. How to online the service groups in VCS ?
Ans: hagrp -offline (service_group) -sys (system_name)
11.What is jeopardy in vcs
The state in which a node is missing one of the two required heartbeat connections. When a node is running with one heartbeat only (in jeopardy), VCS does not restart the applications on a new node. This action of disabling failover is a safety mechanism that prevents data corruption.
12.What is split brain in vcs
Ans : A split brain occurs when two independent systems configured in a cluster assume they have exclusive access to resource. this scenario can be caused when all cluster heartbeat links are simultaneously lost. Each cluster node will then mark the other cluster node as FAULTED. , usually resulting in data corruption.
13. Cluster Log File location
/var/VRTSvcs/log/engine_A.log
14 . command to Verifying that links are active for LLT
Ans: lltstat –n
15. How can I shutdown VCS without shutting down my applications?
Ans :- (1) hastop -all -force (shuts down VCS on all nodes)
(2) hastop -local -force (shuts down VCS on the local node only)
13. What's the difference between Agents and Resources?
Ans : Agents are VCS processes that control and monitor the Resources. Resources are all those objects in your Service Group, and they all require Agents
14.how to Change configuration to read/write mode
Ans :- haconf –makerw
15. what is freeze in vcs
Ans Freeze a service group to prevent it from failing over to another system.
16. Can I run different versions of VCS in the same cluster?
Ans :- No, absolutely not! Different versions of VCS, and even different patch levels of VCS, cannot run at the same time in the same cluster. Therefore, when you install VCS patches, you must install them on *all* nodes at the same time!
17.Difference in critical and non-critical resource
Ans :- 1.(NON-critical ) resource fails , service group will not fail over
2.(Critical ) resource fails , service group will fail over
18. Command to clear the faulty resource
Ans hares -clear (resource-name) -sys (faulted-system)
19. what is the command to Starting and stopping LLT
Ans lltconfig -c
lltconfig -U
20 .Starting and stopping GAB
Ans gabconfig -c -n seed_number
gabconfig –U
21. command to check vcs licence
Ans vxlicense –p
22. command to list the list the parameters of a resource
Ans hares -display
23. command to freeze the service group
Ans hagrp -freeze
Ans: hastatus –sum
2. Which is the main config file for VCS and where it is located?
Ans: main.cf is the main configuration file for VCS and it is located in /etc/VRTSvcs/conf/config.
3. Which command you will use to check the syntax of the main.cf ?
Ans: hacf -verify /etc/VRTSvcs/conf/config
4. How will you check the status of individual resources of VCS cluster?
Ans: hares –state
5. What is the service group in VCS ?
Ans: Service group is made up of resources and their links which you normally requires to maintain the HA of application.
6. What is the use of halink command ?
Ans: halink is used to link the dependencies of the resources
7. What is the difference between switchover and failover ?
Ans: Switchover is an manual task where as failover is automatic. You can switchover service group from online cluster node to offline cluster node in case of power outage, hardware failure, schedule shutdown and reboot. But the failover will failover the service group to the other node when VCS heartbeat link down, damaged, broken because of some disaster or system hung.
8. What is the use of hagrp command ?
Ans: hagrp is used for doing administrative actions on service groups like online, offline, switch etc.
9. How to switchover the service group in VCS ?
Ans: hagrp -switch (service_group) -to (system_name)
10. How to online the service groups in VCS ?
Ans: hagrp -offline (service_group) -sys (system_name)
11.What is jeopardy in vcs
The state in which a node is missing one of the two required heartbeat connections. When a node is running with one heartbeat only (in jeopardy), VCS does not restart the applications on a new node. This action of disabling failover is a safety mechanism that prevents data corruption.
12.What is split brain in vcs
Ans : A split brain occurs when two independent systems configured in a cluster assume they have exclusive access to resource. this scenario can be caused when all cluster heartbeat links are simultaneously lost. Each cluster node will then mark the other cluster node as FAULTED. , usually resulting in data corruption.
13. Cluster Log File location
/var/VRTSvcs/log/engine_A.log
14 . command to Verifying that links are active for LLT
Ans: lltstat –n
15. How can I shutdown VCS without shutting down my applications?
Ans :- (1) hastop -all -force (shuts down VCS on all nodes)
(2) hastop -local -force (shuts down VCS on the local node only)
13. What's the difference between Agents and Resources?
Ans : Agents are VCS processes that control and monitor the Resources. Resources are all those objects in your Service Group, and they all require Agents
14.how to Change configuration to read/write mode
Ans :- haconf –makerw
15. what is freeze in vcs
Ans Freeze a service group to prevent it from failing over to another system.
16. Can I run different versions of VCS in the same cluster?
Ans :- No, absolutely not! Different versions of VCS, and even different patch levels of VCS, cannot run at the same time in the same cluster. Therefore, when you install VCS patches, you must install them on *all* nodes at the same time!
17.Difference in critical and non-critical resource
Ans :- 1.(NON-critical ) resource fails , service group will not fail over
2.(Critical ) resource fails , service group will fail over
18. Command to clear the faulty resource
Ans hares -clear (resource-name) -sys (faulted-system)
19. what is the command to Starting and stopping LLT
Ans lltconfig -c
lltconfig -U
20 .Starting and stopping GAB
Ans gabconfig -c -n seed_number
gabconfig –U
21. command to check vcs licence
Ans vxlicense –p
22. command to list the list the parameters of a resource
Ans hares -display
23. command to freeze the service group
Ans hagrp -freeze
How to set VCS configuration file (main.cf) ro/rw ?
To set the configuration file in read-only/read-write :# haconf -dump -makero (Dumps in memory configuration to main.cf and makes it read-only)
# haconf -makerw (Makes configuration writable)
Where is the VCS engine log file located ?
The VCS cluster engine logs is located at /var/VRTSvcs/log/engine_A.log. We can either directly view this file or use command line to view it :# hamsg engine_A
How to check the complete status of the cluster
To check the status of the entire cluster :# hastatus -sum
How to verify the syntax of the main.cf file
To verify the syntax of the main.cf file just mention the absolute directory path to the main.cf file :# hacf -verify /etc/VRTSvcs/conf/config
What are the different resource types ?
1. Persistent : VCS can only monitor these resources but can not offline or online them.2. On-Off : VCS can start and stop On-Off resource type. Most resources fall in this category.
3. On-Only : VCS starts On-Only resources but does not stop them. An example would be NFS daemon. VCS can start the NFS daemon if required, but can not take it offline if the associated service group is take offline.
Explain the steps involved in Offline VCS configuration
1. Save and close the configuration :# haconf -dump -makero2. Stop VCS on all nodes in the cluster :
# hastop -all3. Edit the configuration file after taking the backup and do the changes :
# cp -p /etc/VRTSvcs/conf/config/main.cf /etc/VRTSvcs/conf/config/main.cf_17march
# vi /etc/VRTSvcs/conf/config/main.cf4. Verify the configuration file syntax :
# hacf -verify /etc/VRTSvcs/conf/config/5. start the VCS on the system with modified main.cf file :
# hastart6. start VCS on other nodes in the cluster.
Note :
This can be done in another way by just stopping VCS and leaving services
running to minimize the downtime. (hastop -all -force
GAB, LLT and HAD
What is GAB, LLT and HAD and whats their functionalities ?
GAB, LLT and HAD forms the basic building blocks of vcs functionality.LLT (low latency transport protocol) – LLT transmits the heartbeats over the interconnects. It is also used to distribute the inter system communication traffic equally among all the interconnects.
GAB (Group membership services and atomic broadcast) – The group membership service part of GAB maintains the overall cluster membership information by tracking the heartbeats sent over LLT interconnects. The atomic broadcast of cluster membership ensures that every node in the cluster has same information about every resource and service group in the cluster.
HAD (High Availability daemon) – the main VCS engine which manages the agents and service group. It is in turn monitored by a daemon named hashadow.
What are the various GAB ports and their functionalities ?
a --> gab driver
b --> I/O fencing (to ensure data integrity)
d --> ODM (Oracle Disk Manager)
f --> CFS (Cluster File System)
h --> VCS (VERITAS Cluster Server: high availability daemon, HAD)
o --> VCSMM driver (kernel module needed for Oracle and VCS interface)
q --> QuickLog daemon
v --> CVM (Cluster Volume Manager)
w --> vxconfigd (module for cvm)
How to check the status of various GAB ports on the cluster nodes
To check the status of GAB ports on various nodes :# gabconfig -a
Whats the maximum number of LLT links (including high and low priority) can a cluster have ?
A cluster can have a maximum of 8 LLT links including high and low priority LLT links.How to check the detailed status of LLT links ?
The command to check detailed LLT status is :# lltstat -nvv
What are the various LLT configuration files and their function ?
LLT uses /etc/llttab to set the configuration of the LLT interconnects.# cat /etc/llttab
set-node node01
set-cluster 02
link nxge1 /dev/nxge1 - ether - -
link nxge2 /dev/nxge2 - ether - -
link-lowpri /dev/nxge0 – ether - -Here, set-cluster -> unique cluster number assigned to the entire cluster [ can have a value ranging between 0 to (64k - 1) ]. It should be unique across the organization.
set-node -> a unique number assigned to each node in the cluster. Here the name node01 has a corresponding unique node number in the file /etc/llthosts. It can range from 0 to 31.
Another configuration file used by LLT is – /etc/llthosts. It has the cluster-wide unique node number and nodename as follows:
# cat /etc/llthosts
0 node01
1 node02LLT has an another optional configuration file : /etc/VRTSvcs/conf/sysname. It contains short names for VCS to refer. It can be used by VCS to remove the dependency on OS hostnames.
What are various GAB configuration files and their function ?
The file /etc/gabtab contains the command to start the GAB.# cat /etc/gabtab
/sbin/gabconfig -c -n 4here -n 4 –> number of nodes that must be communicating in order to start VCS.
How to start/stop GAB
The commands to start and stop GAB are :
# gabconfig -c (start GAB)
# gabconfig -U (stop GAB)
How to start/stop LLT
The commands to stop and start LLT are :# lltconfig -c -> start LLT
# lltconfig -U -> stop LLT (GAB needs to stopped first)
What’s a GAB seeding and why manual GAB seeding is required ?
The GAB configuration file /etc/gabtab defines the minimum number of nodes that must be communicating for the cluster to start. This is called as GAB seeding.In case we don’t have sufficient number of nodes to start VCS [ may be due to a maintenance activity ], but have to do it anyways, then we have do what is called as manual seeding by firing below command on each of the nodes.
# gabconfig -c -x
How to start HAD or VCS ?
To start HAD or VCS on all nodes in the cluster, the hastart command need to be run on all nodes individually.# hastart
What are the various ways to stop HAD or VCS cluster ?
The command hastop gives various ways to stop the cluster.# hastop -local
# hastop -local -evacuate
# hastop -local -force
# hastop -all -force
# hastop -all
-local -> Stops
service groups and VCS engine [HAD] on the node where it is fired
-local -evacuate -> migrates Service groups on the node where it is fired and stops HAD on the same node only
-local -force -> Stops HAD leaving services running on the node where it is fired
-all -force -> Stops HAD on all the nodes of cluster leaving the services running
-all -> Stops HAD on all nodes in cluster and takes service groups offline
-local -evacuate -> migrates Service groups on the node where it is fired and stops HAD on the same node only
-local -force -> Stops HAD leaving services running on the node where it is fired
-all -force -> Stops HAD on all the nodes of cluster leaving the services running
-all -> Stops HAD on all nodes in cluster and takes service groups offline
Resource Operations
How to list all the resource dependencies
To list the resource dependencies :# hares -dep
How to enable/disable a resource ?
# hares -modify [resource_name] Enabled 1 (To enable a resource)
# hares -modify [resource_name] Enabled 0 (To disable a resource)
How to list the parameters of a resource
To list all the parameters of a resource :# hares -display [resource]
Service group operations
How to add a service group(a general method) ?
In general, to add a service group named SG with 2 nodes (node01 and node02) :haconf –makerw
hagrp –add SG
hagrp –modify SG SystemList node01 0 node02 1
hagrp –modify SG AutoStartList node02
haconf –dump -makero
How to check the configuration of a service group – SG ?
To see the service group configuration :# hagrp -display SG
How to bring service group online/offline ?
To online/offline the service group on a particular node :# hagrp -online [service-group] -sys [node] (Online the SG on a particular node)
# hagrp -offline [service-group] -sys [node] (Offline the SG on particular node)
The -any option when used instead of the node name, brings the SG
online/offline based on SG’s failover policy.# hagrp -online [service-group] -any
# hagrp -offline [service-group] -any
How to switch service groups ?
The command to switch the service group to target node :# hagrp -switch [service-group] -to [target-node]
How to freeze/unfreeze a service group and what happens when you do so ?
When you freeze a service group, VCS continues to monitor the service group, but does not allow it or the resources under it to be taken offline or brought online. Failover is also disable even when a resource faults. When you unfreeze the SG, it start behaving in the normal way.To freeze/unfreeze a Service Group temporarily :
# hagrp -freeze [service-group]
# hagrp -unfreeze [service-group]To freeze/unfreeze a Service Group persistently (across reboots) :
# hagrp -freeze -persistent[service-group]
# hagrp -unfreeze [service-group] -persistent
Communication failures : Jeopardy, split brain
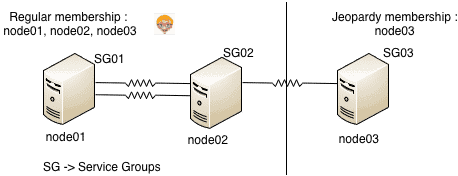
Whats a Jeopardy membership in vcs clusters
When a node in the cluster has only the last LLT link intact, the node forms a regular membership with other nodes with which it has more than one LLT link active and a Jeopardy membership with the node with which it has only one LLT link active.Effects of jeopardy : (considering example in diagram above)
1. Jeopardy membership formed only for node03
2. Regular membership between node01, node02, node03
3. Service groups SG01, SG02, SG03 continue to run and other cluster functions remain unaffected.
4. If node03 faults or last link breaks, SG03 is not started on node01 or node02. This is done to avoid data corruption, as in case the last link is broken the nodes node02 and node01 may think that node03 is down and try to start SG03 on them. This may lead to data corruption as same service group may be online on 2 systems.
5. Failover due to resource fault or operator request would still work.
How to recover from a jeopardy membership ?
To recover from jeopardy, just fix the failed link(s) and GAB automatically detects the new link(s) and the jeopardy membership is removed from node.Whats a split brain condition ?
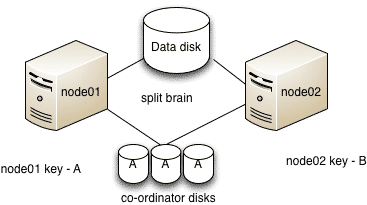
Split brain occurs when all the LLT links fails simultaneously. Here systems in the cluster fail to identify whether it is a system failure or an interconnect failure. Each mini-cluster thus formed thinks that it is the only cluster thats active at the moment and tries to start the service groups on the other mini-cluster which he think is down. Similar thing happens to the other mini-cluster and this may lead to a simultaneous access to the storage and can cause data corruption.What is I/O fencing and how it prevents split brain ?
VCS implements I/O fencing mechanism to avoid a possible split-brain condition. It ensure data integrity and data protection. I/O fencing driver uses SCSI-3 PGR (persistent group reservations) to fence off the data in case of a possible split brain scenario.In case of a possible split brain
As show in the figure above assume that node01 has key “A” and node02 has key “B”.
1. Both nodes think that the other node has failed and start racing to write their keys to the coordinator disks.
2. node01 manages to write the key to majority of disks i.e. 2 disks
3. node02 panics
4. node01 now has a perfect membership and hence Service groups from node02 can be started on node01
Whats the difference between MultiNICA and MultiNICB resource types ?
MultiNICA and IPMultiNIC– supports active/passive configuration.
– Requires only 1 base IP (test IP).
– Does not require to have all IPs in the same subnet.
MultiNICB and
IPMultiNICB
– supports active/active configuration.
– Faster failover than the MultiNICA.
– Requires IP address for each interface.
– supports active/active configuration.
– Faster failover than the MultiNICA.
– Requires IP address for each interface.
Troubleshooting
How to flush a service group and when its required ?
Flushing of a service group is required when, agents for the resources in the service group seems suspended waiting for resources to be taken online/offline. Flushing a service group clears any internal wait states and stops VCS from attempting to bring resources online.To flush the service group SG on the cluster node, node01 :
# hagrp -flush [SG] -sys node01
How to clear resource faults ?
To clear a resource fault, we first have to fix the underlying problem.1. For persistent resources :
Do not do anything and wait for the next OfflineMonitorInterval (default – 300 seconds) for the resource to become online.
2. For non-persistent resources :
Clear the fault and probe the resource on node01 :
# hares -clear [resource_name] -sys node01
# hares -probe [resource_name] -sys node01
How to clear resources with ADMIN_WAIT state ?
If the ManageFaults attribute of a service group is set to NONE, VCS does not take any automatic action when it detects a resource fault. VCS places the resource into the ADMIN_WAIT state and waits for administrative intervention.1. To clear the resource in ADMIN_WAIT state without faulting service group :
# hares -probe [resource] -sys node012. To clear the resource in ADMIN_WAIT state by changing the status to OFFLINE|FAULTED :
# hagrp -clearadminwait -fault [SG] -sys node01
Advanced Operations
How to add/remove a node from an active VCS cluster online
To add a node to cluster refer the article :To remove a node from the cluster refer the article :
How to configure I/O fencing
For detailed steps on configuring I/O fencing refer the post :How to add/remove LLT links to/from VCS cluster
To add/remove LLT links refer detailed steps in the post :
Q: – What is a Veritas Cluster
server or VCS cluster ?
VERITAS Cluster Server (VCS) from
Symantec connects multiple, independent systems into a management framework for
increased availability. Each system, or node, runs its own operating system and
cooperates at the software level to form a cluster. VCS links commodity
hardware with intelligent software to provide application failover and control.
When a node or a monitored application fails, other nodes can take predefined
actions to take over and bring up services elsewhere in the cluster.
Q: – What are types of cluster ?
Cluster is an broadly used term and
broadly classified as
– High Availability (HA) clusters
– Parallel processing clusters
– Load balancing clusters
– Parallel processing clusters
– Load balancing clusters
High Performance Computing (HPC)
clusters
VCS is primarily an HA cluster
–With support for some key parallel processing applications like Oracle RAC
–With support for some key parallel processing applications like Oracle RAC
Q: – What are Veritas Cluster or VCS
User Account Privileges ?
Cluster Administrator:- Full Privileges
Cluster Operator:- All cluster, service group, and resources-level
operations.
Cluster Guest :- Read-only access: new users created as cluster
guest accounts by default.
Group Administrator :- All service group operations for a specified service
group,except deleting service group.
Group Operator :- Bring service groups and resources online and take
offline, temporarily freeze or unfreeze service groups
Q: – What are SwitchOver and
Failover in Veritas Cluster ?
Switchover: A switchover is an orderly shutdown of an application and
it’s supporting resources on one server and a controlled startup on another
server.
Failover : A failover is similar to a switchover, except the ordered
shutdown of applications on the original node may not be possible, so the
services are started on another node.
Q: – Definition of a Service Group
in Veritas Cluster ?
A service group is a virtual container
that enables VCS to manage an application service as a unit.All components
required to provide the service, and the relationships between these
components, are defined within the service group.Service groups have attributes
that define its behavior, such as where it can start and run.
Q: – What are Service Group Types ?
Failover:
– The service group can be online on only one cluster system at a time.
– VCS migrates the service group at the administrator’s request and in response to faults.
– The service group can be online on only one cluster system at a time.
– VCS migrates the service group at the administrator’s request and in response to faults.
Parallel:
The service group can be online on multiple cluster systems simultaneously.
An example is Oracle Real Application Clusters (RAC).
The service group can be online on multiple cluster systems simultaneously.
An example is Oracle Real Application Clusters (RAC).
Q: – How to specify Service Group
Dependencies in veritas Cluster ?
We can use service group
dependencies to specify most application relationships according to these four
criteria:
– Category: Online or offline
– Location: Local, remote, or global
– Startup behavior: Parent or child
– Failover behavior: Soft, firm, or hard
– Category: Online or offline
– Location: Local, remote, or global
– Startup behavior: Parent or child
– Failover behavior: Soft, firm, or hard
We can specify combinations of these
characteristics to determine how dependencies affect service group behavior.
Q: – Define the Resources in veritas
cluster ?
Resources are VCS objects that
correspond to the hardware or software components of an application service.
- Each resource must have a unique name throughout the cluster. Choosing names that reflect the service group name makes it easy to identify all the resources in that group, for example, WebIP in the WebSG group.
- Resources are always contained within service groups.
- Resource categories include: Persistent & Nonpersistent
Q: – What are On-Off &
Persistent Resources ?
On-Off:- VCS starts and stops On-Off resources as required. For
example, VCS imports a disk group when required, and deports it when it is no
longer needed.
Persistent:- These resources cannot be brought online or taken offline.
For example, a network interface card cannot be started or stopped, but it is
required to configure an IP address. A Persistent resource has an operation
value of none. VCS monitors Persistent resources to ensure their status and
operation. Failure of a Persistent resource triggers a service group failover.
Q: – What are Agents in Veritas
cluster or VCS cluster ?
Agents are multi-threaded processes
that provide the logic to manage resources. VCS has one agent per resource
type. The agent monitors all resources of that type; for example, a single IP
agent manages all IP resources. When the agent is started, it obtains the
necessary configuration information from VCS. It then periodically monitors the
resources, and updates VCS with the resource status. An agent typically brigs
resources online, take resources offlineand monitors resources to determine
their state.
Q: – How VCS Controls Resources ?
Each resource type has a
corresponding agent process that manages all resources of that type.
- Agents have one or more entry points that perform a set of actions on resources.
- Each system runs one agentfor each active resource type
Q: – What are the main functions of
LLT,GAB & HAD in veritas cluster ?
Low-Latency Transport(LLT) :-
- Is responsible for sending heartbeat messages
- Transports cluster communication traffic to every active system
- Balances traffic load across multiple network links
- Maintains the communication link state
- Is a nonroutable protocol
- Runs on an Ethernet network
Group Membership Services/Atomic
Broadcast (GAB)
- Performs two functions:
– Manages cluster membership;
referred to as GAB membership.
– Sends and receives atomic broadcasts of configuration information
– Sends and receives atomic broadcasts of configuration information
- Is a proprietary broadcast protocol
- Uses LLT as its transport mechanism
The High Availability Daemon (HAD)
The VCS engine, the high
availability daemon:
– Runs on each system in the cluster
– Maintains configuration and state information for all cluster resources
– Manages all agents
– Maintains configuration and state information for all cluster resources
– Manages all agents
The hashadow daemon monitors HAD.
Q: – What are Failover Policies in
Veritas Cluster ?
The FailOverPolicy attribute
specifies how a target system is selected:
– Priority: The system with the lowest priority number in the list is selected (default).
– RoundRobin: The system with the least number of active service groups is selected.
– Load: The system with greatest available capacity is selected.
– Priority: The system with the lowest priority number in the list is selected (default).
– RoundRobin: The system with the least number of active service groups is selected.
– Load: The system with greatest available capacity is selected.
Example configuration: hagrp –modify
groupname FailOverPolicy Load
Solaris:
Q: Are you working cluster environment ?
A:Yes.I am working Veritas cluster .Its a zone failover model cluster.
(:- Here interviewers will try to screw you by asking the cluster setup.The next question will be …
Q:Zone failover model cluster ? How it works ?
A: Veritas cluster software has been installed on two global zones and configured .
We have configured the failover service group and added the zone as resource.zones are installed on shared storage and LUNS are visible on both the cluster nodes.If there is any issue on one global zone ,the service group will automatically fail-overs to second global zone.In other words, zone will be halted on one node and booted in other node.
This kind of cluster setup is very less compare to the traditional & complex start/stop scripts for application.
Off-course without having the hands on experience ,it is hard to explain with confidence.So Practice the VCS cluster yourself before attending any interviews.
There are three article in Unixarena to get the setup to be done on VMWARE workstation to practice yourself.
1.How to install and configure two node VCS cluster.
2.Create a new service on veritas cluster.
3.Add the zone as resource in service group.
Redhat Linux:
The same trick you can follow on the Linux interview as well. Redhat Cluster as well supports the virtual machine failover. If the interviewer ask about the redhat cluster, you simply say that ” I am working two node redhat cluster – virtual machine failover setup”.
Here is the overview of the virtual machine failover setup using redhat cluster.
Q: Are you working cluster environment ?
A:Yes.I am working Veritas cluster .Its a zone failover model cluster.
(:- Here interviewers will try to screw you by asking the cluster setup.The next question will be …
Q:Zone failover model cluster ? How it works ?
A: Veritas cluster software has been installed on two global zones and configured .
We have configured the failover service group and added the zone as resource.zones are installed on shared storage and LUNS are visible on both the cluster nodes.If there is any issue on one global zone ,the service group will automatically fail-overs to second global zone.In other words, zone will be halted on one node and booted in other node.
This kind of cluster setup is very less compare to the traditional & complex start/stop scripts for application.
Off-course without having the hands on experience ,it is hard to explain with confidence.So Practice the VCS cluster yourself before attending any interviews.
There are three article in Unixarena to get the setup to be done on VMWARE workstation to practice yourself.
1.How to install and configure two node VCS cluster.
2.Create a new service on veritas cluster.
3.Add the zone as resource in service group.
Redhat Linux:
The same trick you can follow on the Linux interview as well. Redhat Cluster as well supports the virtual machine failover. If the interviewer ask about the redhat cluster, you simply say that ” I am working two node redhat cluster – virtual machine failover setup”.
Here is the overview of the virtual machine failover setup using redhat cluster.
Redhat
cluster has been installed on both the cluster nodes and configured as two node
cluster.We have KVM packages installed and configured with the virtual guests on
both the nodes.Those virtual guests aka virtual servers have added in to
the redhat cluster as resource and if there is any issues with one server, all
the virtual machine will be halted/killed and those will be booted on
the second cluster node.
The beauty of redhat cluster + KVM is that virtual machines can be failover to other node without hating/rebooting it .
The beauty of redhat cluster + KVM is that virtual machines can be failover to other node without hating/rebooting it .
The
below articles will be help you to setup the environment redhat cluster
environment.
1.Configure the redhat cluster with virtual machine.
2.Test the live migration for the virtual guests.
Hope now you can able to manage the cluster related questions in interview.
I am sure that if you explain these setup with confidence, definitely interviewer will not ask further question on this.
1.Configure the redhat cluster with virtual machine.
2.Test the live migration for the virtual guests.
Hope now you can able to manage the cluster related questions in interview.
I am sure that if you explain these setup with confidence, definitely interviewer will not ask further question on this.
Q: – What is clusterring and why we
use clustering ?
The concept of a cluster is that the
cluster itself appears on the outside as a single system. A cluster consists of
two or more Real Computers referred to as nodes or members of a cluster. The
components of a cluster are commonly, but not always, connected to each other
through fast Local Area Networks.
Clusters are usually deployed to
improve performance and/or availability over that provided by a single
computer, while typically being much more cost-effective than single computers
of comparable speed or availability. Clustering is all about the back-end
operations being performed by the nodes or members which appear to the outside
world as a single computational entity.
Q: – What are the different type of
clusters ?
1. High Performance Clusters
2. High Availability Clusters
3. Load Balancing clusters
4. Storage Clusters
2. High Availability Clusters
3. Load Balancing clusters
4. Storage Clusters
Q: – What is High Performance
Clusters ?
In High Performance Clusters
Multiple nodes in cluster perform concurrent calculations. There are two key
benefits of High Performance (or grid) computing :
Resilience –> As long as even a
single member of a cluster is running, services continue to be provided by the
cluster
Increased Capacity –> The more
nodes added to the cluster, the more computing horsepower is available and
therefore very powerful computers can be built using
commodity hardware
commodity hardware
Q: – What is High Availabilty
Clusters (HA) ?
High-availability clusters provide
continuous availability of services by eliminating single points of failure and
by failing over services from one cluster node to another in case a node
becomes inoperative.High-availability clusters are sometimes referred to as
failover clusters. Red Hat Cluster Suite provides high-availability clustering
through its High-availability Service Management component.
Q: – What is Load Balancing Clusters
?
Load Balancing Clusters operate by
having all workload come through one or more load balancing front-ends, which
then distribute it to a collection of back end servers. If a node in a
load-balancing cluster becomes inoperative, the load-balancing software detects
the failure and redirects requests to other cluster nodes. Red Hat Cluster
Suite provides load- balancing through LVS (Linux Virtual Server).
Q: – What is Storage Clusters ?
Storage clusters provide a consistent
file system image across servers in a cluster, allowing the servers to
simultaneously read and write to a single shared file system.With a
cluster-wide file system, a storage cluster eliminates the need for
redundantcopies of application data and simplifies backup and disaster
recovery. Red Hat Cluster Suite provides storage clustering through Red Hat
GFS.
Q: – What is Active Passive and
Active Active Terminology in HA Clusters ?
Active/Passive Terminology generally
refers to failover clusters running only one service.
Active/Active Terminology can be
used to refer to :
Failover clusters with multiple servers such that all cluster members are hosting at least one service
Failsafe Clusters
Failover clusters with multiple servers such that all cluster members are hosting at least one service
Failsafe Clusters
Q: – What is Fencing in Clustering ?
Fencing is used to avoid data inconsistencies
in shared storage by fencing or cutting off a failed member.When the cluster
manager detects a member failure, it immediately cuts off the failed member
from accessing shared resources.Fence Devices can either be shared or
non-shared.
Q: – What are Clustering Hardware
Requirements ?
Red Hat Certified Hardware capable
of running the proposed OS (RHEL 3/4/5)
Ethernet Switch for Networking
Fencing Hardware
Shared Storage (for services that require access to shared data)
Ethernet Switch for Networking
Fencing Hardware
Shared Storage (for services that require access to shared data)
Q: – What is GFS2 filesystem ?
GFS2 is a shared file system used by
Red Hat Cluster node member simultaneously. GFS2 allows all nodes to have
direct concurrent access to the same shared block storage. In addition, GFS2
can also be used as a local filesystem. The principle component to allow such
access is lock management. GFS2 uses DLM or Distributed Lock Management to
achieve this. Also clustered LVM is used to communicate LVM meta data changes
across nodes.
Q: – What is fencing in clustering
and why it is required ?
Fencing is the process of isolating
a node of a computer cluster when the former is malfunctioning. Isolating
a node means ensuring that I/O can no longer be done from it. Fencing is
typically done automatically, by cluster infrastructure such as shared
disk file systems, in order to protect processes from other active nodes
modifying the resources during node failures.
Fencing is required because it is
impossible to distinguish between a real failure and a temporary hang. If the
alfunctioning node is really down, then it cannot do any damage, so
theoretically no action would be required (it could simply be brought back into
the cluster with the usual join process). However, because there is a
possibility that a malfunctioning node could itself consider the rest of the
cluster to be the one that is malfunctioning, a race condition could ensue, and
cause data corruption. Instead, the system has to assume the worst scenario and
always fence in case of problems
Q: – what is Quorum ?
Quorum is a voting algorithm used by
the cluster manager. A cluster can only function correctly if there is general
agreement between the members about things. We say a cluster has ‘quorum’ if a
majority of nodes are alive, communicating, and agree on the active cluster
members. So in a thirteen-node cluster, quorum is only reached if seven or more
nodes are communicating. If the seventh node dies, the cluster loses quorum and
can no longer function. It’s necessary for a cluster to maintain quorum to
prevent ‘splitbrain’ problems.
Q: – What is multipathing in
clustering ?
Clusters should be designed with
NSPOF(No Single Point Of Failure) considerations. That means that there should
be no single device such that it’s failure could impact the Cluster. As an
example, when using Fibre HBAs, two HBAs must be put into each clustered Node
to guard against card failure, link failure etc. Similarly, two Fibre Switches
should be used to prevent cluster services disruption int he event of the
switch failure. If iSCSI protocol is used to access the shared storage, then
two network cards should be used for this purpose. Each network card should
have a unique IP address and should be connected via different switched to the
iSCSI Storage.
Q: – Describe how the storage will
be accessed using the iSCSI protocol in clustered environment ?
iSCSI is used to facilitate data
transfers over intranets and to manage storage over long distances. iSCSI can
be used to transmit data over local area networks (LANs), wide area networks
(WANs), or the Internet and can enable location-independent data storage and
retrieval. The protocol allows clients (called initiators) to send SCSI
commands (CDBs) to SCSI storage devices (targets) on remote servers. It is a
popular Storage Area Network (SAN) protocol, allowing organizations to
consolidate storage into data center storage arrays while providing hosts (such
as database and web servers) with the illusion of locally-attached disks.
Unlike traditional Fibre Channel, which requires special purpose cabling, iSCSI
can be run over long distances using existing network infrastructure.
Q: – What are the Logical Steps for
installing Red Hat Cluster Suite ?
a) Configure
Storage/udev/multipathing
b) Test file systems by mounting on both nodes
c) Install application on both nodes and copy required folders/data to shared
storage
d) Write the startup/shutdown/status scripts, if required (you can use standard sysv
inti scripts as well, if you application has one)
e) Mount the shared partition on node1 and test the app
f) Unmount shared partition from node1, mount in node2 and test the app
g) Test fencing from both nodes
h) install cman, rgmanager rpms
i) Ensure iptables and selinux do not interfere (setenforce 0 for selinux)
b) Test file systems by mounting on both nodes
c) Install application on both nodes and copy required folders/data to shared
storage
d) Write the startup/shutdown/status scripts, if required (you can use standard sysv
inti scripts as well, if you application has one)
e) Mount the shared partition on node1 and test the app
f) Unmount shared partition from node1, mount in node2 and test the app
g) Test fencing from both nodes
h) install cman, rgmanager rpms
i) Ensure iptables and selinux do not interfere (setenforce 0 for selinux)




{kind=link}
{kind=link}
Nice and good blog.I have suggested to my friends to go through this blog. Thanks for sharing this useful information. If you want to learn Linux course in online, please visit below site.
ReplyDeleteLinux Online Training
linux online course
Linux Online Training in Hyderabad
Linux Online Training in Bangalore
Veritas Cluster Interview Questions ~ System Admin Stuff >>>>> Download Now
ReplyDelete>>>>> Download Full
Veritas Cluster Interview Questions ~ System Admin Stuff >>>>> Download LINK
>>>>> Download Now
Veritas Cluster Interview Questions ~ System Admin Stuff >>>>> Download Full
>>>>> Download LINK